
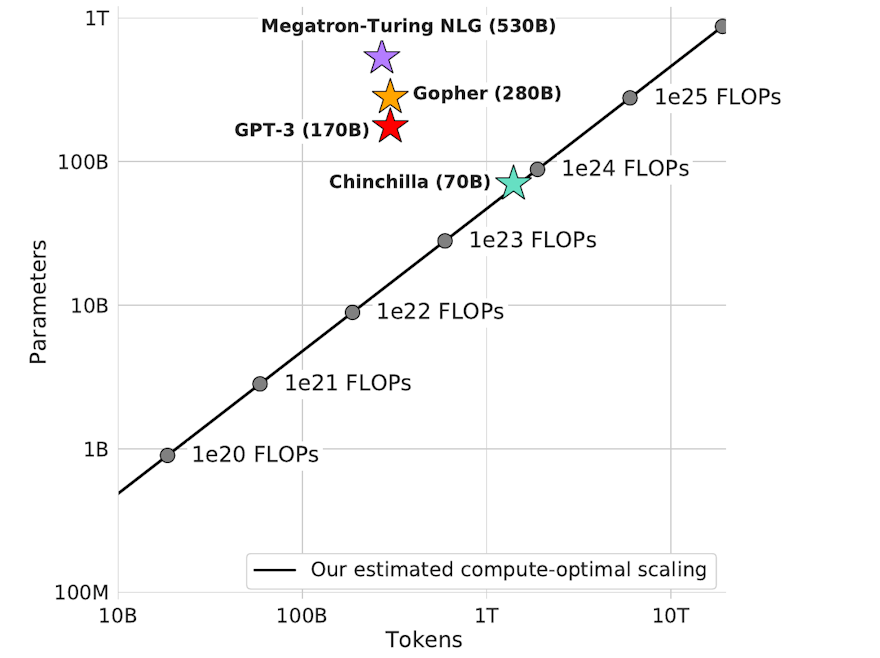
Un résultat susceptible de freiner un tout petit peu la course vers les modèles gigantesques en NLP. Les auteurs de ce papier, qui nous vient de DeepMind, montrent que les performances des gros modèles de deep learning, de type Transformer, ne suivent pas nécessairement le nombre de paramètres à quantité constante de données d'entraînement - ce qui est devenu pourtant une pratique courante ces dernières années. Autrement dit, les plus gros modèles disponibles aujourd'hui (Gopher, GPT-3, etc.) sont en réalité sous-entraînés. Les auteurs ont ainsi entraîné un plus petit modèle (70 milliards de paramètres quand même !) sur 1400 milliards de tokens et ce modèle, baptisé Chinchilla, s'est révélé plus performant que GPT-3, Gopher, MT NLG - qui possèdent, respectivement, 175 milliards, 280 milliards et 530 milliards de paramètres. Ils donnent même une sorte de loi empirique sur la quantité de données d'entraînement optimale par nombre de paramètres. Au-delà de freiner - très modérément - cette course folle vers le gigantisme, cela nous rappelle encore que l'importance des données par rapport aux modèles.